Announcing Wikimapper
My current NLP research is about Entity Linking, that is disamiguating a mention, e.g. Obama with regard to a knowledge base. When using Wikidata for that, it would be linked to Q76. It is a difficult problem to create an automatic system for that, as mentions are often very ambiguous. For instance when linking Obama, possible candidates are among others Barack Obama, his wife Michelle Obama or even a city in Japan.
Entity linking research uses a wide variety of corpora to evaluate the performance of algorithms for automatic disambiguation. Many of these use Wikipedia as a knowledge base, linking mentions in a text with its Wikipedia page. One of these is the AIDA CoNLL-YAGO Dataset. I implemented an approach that works with Wikidata instead of Wikipedia, as I then could use SPARQL for implementing certain features, e.g. semantic similarity based on neighbours of an entity in the knowledge graph.
To use my approach and evaluate it on Wikipedia-based corpora, I needed to map Wikipedia page URLs to Wikidata items. A quick Google search told me that I could use the official Wikidata SPARQL endpoint. To find the Wikidata ID of our beloved Manatees, the query looks the following:
prefix schema: <http://schema.org/>
SELECT * WHERE {
<https://en.wikipedia.org/wiki/Manatee> schema:about ?item .
}
This works and retrieves Q42797, but has
several issues: First, it uses the network, which is slow. Second, I try to use
that endpoint as infrequent as possible to save their resources (my use case is
to map data sets that have easily tens of thousands of entries). Third, I had
coverage issues due to redirects in Wikipedia not being resolved (around ~20% of
the time for some older data sets). You can try it out, pages like e.g.
https://en.wikipedia.org/wiki/Ceylon do not work, it redirects to
https://en.wikipedia.org/wiki/Sri_Lanka and the SPARQL endpoint does not catch
that.
Therefore, I created a Python package called
wikimapper. To install, just use pip install wikimapper. It uses Wikipedia SQL dumps to create an index once for a
certain language Wiki so the lookups are quite fast.
When looking for how to do the mapping, I noticed that the Wikipedia pages have
a link called Wikidata item. This means that the Wikidata ID needs to be saved
somewhere in the Wikipedia dumps. This is nice, as these are much smaller than
Wikidata dumps. I then looked at the Wikipedia SQL table
layout for the tables of
interest. These are page (page id and title), page_props (Wikidata ID) and
redirect (propagating Wikidata IDs to pages that are only redirects).
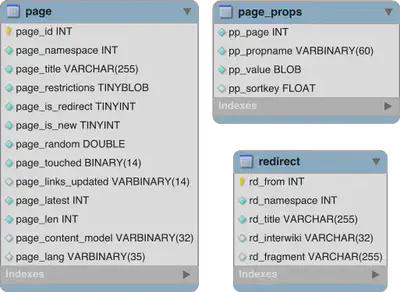
jamesmishra has noticed that SQL dumps from Wikipedia almost look like CSV. He provides some basic functions to parse insert statements into tuples. I then use the Wikipedia SQL page dump to get the mapping between title and internal id, page props to get the Wikidata ID for a title and then the redirect dump in order to fill titles that are only redirects and do not have an entry in the page props table.
The code is available on Github under the Apache License. It should should (hopefully!) be sufficiently commented and I tried to make the README as exhaustive as possible. If you encounter problems, have feature requests and/or comments, please use the Github issue tracker or write me to blog@mrklie.com.
Acknowledgements
I am very thankful for jamesmishra to provide mysqldump-to-csv. Also, mbugert helped me tremendously understanding Wikipedia dumps and giving me the idea on how to map.